


Новый дроп от DeepSeek: выложили полностью открытый стек для ускорения генерации LLM…
Новый дроп от DeepSeek: выложили полностью открытый стек для ускорения генерации LLM
Внутри готовые алгоритмы, обучение, эвал и даже пайплайн для данных. Бери и пользуйся, супер практично. github.com/deepseek-ai/DeepSpec
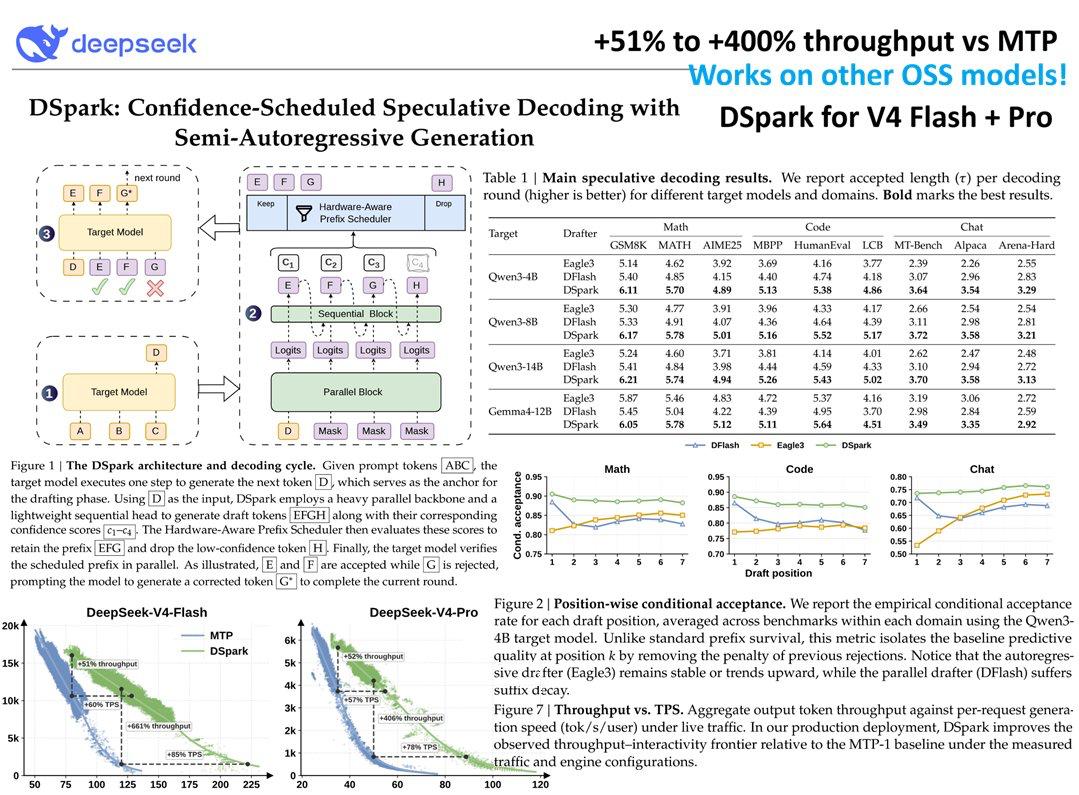
Основная соль – в алгоритме DSpark. Его DeepSeek уже использует для DeepSeek-V4 Flash и Pro в проде, и, по их данным, относительно старого бейзлайна скорость генерации для пользователя выросла примерно на 60–85%.
Как устроен алгоритм:
– Фундаментально, это небольшая модель, которая пишет черновики для основной LLM. Это называется драфт-модель.
– Такой подход сейчас в моде (Google, например, делают такое для Gemma: t.me/data_secrets/9179), но DeepSeek выводят его на новый уровень. Их драфт-модель работает необычно, в два этапа. Сначала параллельно набрасывается блок токенов, а потом легкий марковский модуль уточняет зависимости между соседними токенами. Благодаря такому подходу драфтер и работает быстро, и не очень сыпится в хвостах.
– После того, как драфтер накидал черновик, основная LLM его проверяет и принимает только правильный префикс, корректируя остальное. При этом DSpark сам решает, сколько токенов отправить на проверку, основываясь на оценках уверенности по токенам и текущей нагрузке на железо.
В результате получаем ускорение минимум в 1.5 раза абсолютно без потери качества. Снимаем шляпу перед DeepSeek за такой опенсорс.
Материалы по теме












Вставить свои 5 копеек: