



Парсеры: что это такое, кому и зачем они нужны
Специалисты разных сфер используют парсеры для автоматического сбора и обработки данных. В этой статье объясняем, что такое парсер и кому он может быть полезен, а также представим подборку парсеров, которые могут пригодиться в работе и не требуют больших затрат.
- Что такое парсеры
- Парсер — что это такое и как работает парсинг данных
- Кому и зачем нужны парсеры: примеры использования
- Какой парсер выбрать
- Парсеры по способу доступа к интерфейсу
- Парсеры в зависимости от технологий, которые они используют
- Виды парсеров по задачам и специализации
- Как выбрать парсер под свои задачи: чек-лист критериев
- Почему важно знать, что такое парсер
Арбитражникам, маркетологам и SEO-специалистам приходится работать с огромным количеством информации. Чтобы облегчить свою работу и повысить эффективность, они используют парсеры — инструменты для парсинга данных (веб‑скрапинга), которые автоматически собирают информацию с сайтов.
В этой статье разберемся, что такое парсер и как парсер помогает арбитражникам собирать данные по офферам, источникам трафика и креативам. Также представляем подборку парсеров, которые могут пригодиться в работе специалистам разных сфер и стоят не дорого.
Что такое парсеры
Парсеры — это специализированные программы или онлайн-сервисы, предназначенные для автоматического сбора информации с веб-ресурсов. Они работают на основе синтаксического анализа (парсинга) содержимого HTML-страниц и извлекают из них различные данные: тексты, изображения, таблицы, ссылки и другие элементы.
Парсеры используются в разных сферах, включая SEO-оптимизацию, мониторинг конкурентов, анализ рынка и многие другие. Они позволяют быстро и эффективно собирать информацию с множества источников, экономя время и усилия специалистов.
Работа парсеров состоит из двух основных этапов:
- Сканирование исходного материала (HTML-кода, текста, базы данных и т. д.) с целью выявления интересующих элементов;
- Извлечение и обработка семантически значимых данных.
Полученные данные преобразуются в удобный для изучения формат и систематизируются для дальнейшего использования.
Парсер — что это такое и как работает парсинг данных
Парсеры — это специализированные программы или онлайн-сервисы, предназначенные для автоматического сбора информации с веб-ресурсов. Они работают на основе синтаксического анализа (парсинга) содержимого HTML-страниц и «разбирают» его на отдельные элементы по заданным правилам: тексты, изображения, таблицы, ссылки и другие элементы.
Парсеры для арбитража трафика используются в разных сферах, включая SEO‑оптимизацию, мониторинг конкурентов, анализ рынка, построение витрин офферов и многие другие задачи.
Вместо того чтобы человек вручную копировал тексты, цены или контакты, парсер сайтов последовательно загружает страницы, выделяет нужные блоки (например, карточки товаров или статьи) и извлекает оттуда структурированные данные.
Такой подход позволяет через парсер данных собирать большие массивы информации по единому шаблону, сводить их в таблицы или базы данных и дальше использовать для аналитики, отчетов или загрузки в другие системы. За счет этого специалист быстро видит тренды, сравнивает показатели по множеству источников и может оперативно принимать решения.
Работа парсеров состоит из двух основных этапов:
- Сканирование исходного материала (HTML‑кода, текста, базы данных и т. д.) с целью выявления интересующих элементов, таких как блоки с товарами, заголовки, цены или контактная информация.
- Извлечение и обработка семантически значимых данных — парсер «подчищает» лишнее, приводит значения к нужному формату (например, числа, даты, валюты), сопоставляет поля между собой и готовит их к выгрузке.
Полученные данные преобразуются в удобный для изучения формат — чаще всего это таблицы, CSV‑файлы или записи в базе данных, где каждая строка соответствует отдельному объекту (товару, странице, объявлению), а столбцы — его характеристикам. Далее эти данные можно фильтровать, сортировать, сравнивать между собой, подгружать в BI‑системы, рекламные кабинеты или CRM, что делает парсеры не просто инструментом сбора, а важной частью всей аналитической инфраструктуры.
Простыми словами, что такое парсинг: программа-парсер автоматически ходит по страницам и вытаскивает нужные вам данные — цены, заголовки, контакты, описания товаров. Такой парсер данных экономит время, потому что делает рутинный сбор информации вместо человека и сразу складывает все в удобные таблицы или отчеты.
Кому и зачем нужны парсеры: примеры использования
Парсеры нужны не только тем, кто льет трафик:
- Арбитражники мониторят цены офферов, собирают креативы и ленды конкурентов.
- Маркетологи используют парсер для мониторинга конкурентов и анализа це
- SEO‑специалист использует парсер для SEO-технического аудита и семантики.
- Аналитики собирают с помощью парсера данных информацию о поведении пользователей и их отпечатки.
- Предприниматели автоматизируют бизнес-процессы и управляют большими объемами данных, используют парсеры для мониторинга цен.
Программы для парсинга сайтов позволяют:
- извлекать метаданные сайта (заголовки, описания, теги H1), что важно для SEO-оптимизации;
- собирать данные о ценах и ассортименте товаров, что актуально для интернет-магазинов;
- анализировать техническую составляющую сайта (битые ссылки, ошибки 404, неработающие редиректы) для веб-мастеров и SEO-специалистов.
Какой парсер выбрать
В этом разделе разберем, чем отличаются облачные сервисы, программы, браузерные расширения и решения на Python/PHP, а также в каких случаях что выбирать. Облачные сервисы обычно удобнее для быстрых стартов и командной работы, программы — для стабильного регулярного парсинга на своем компьютере или сервере, браузерные расширения — для разовых выборок прямо из браузера, а решения на Python/PHP — для сложных и нестандартных задач с полной гибкостью настроек.
Мы подробно расскажем о каждом решении и рассмотрим основные характеристики этих парсеров арбитража трафика.
Парсеры по способу доступа к интерфейсу
По типу доступа к интерфейсу парсеры можно разделить на две категории: облачные решения и программы, требующие установки на компьютер.
Парсеры-программы
ПО для парсинга устанавливается на компьютер и чаще всего работает на Windows. Пользователи macOS могут использовать виртуальные машины для запуска таких программ.
Примеры парсеров-программ:
Datacol — это универсальный парсер для интернет‑магазинов и сайтов, который может автоматически собирать данные и файлы и позволяет импортировать и экспортировать информацию в различные форматы. Собранные данные можно загрузить в XLS и CSV, базы данных, перенести в CMS, такие как WordPress, Joomla или Drupal.
Главная страница универсального парсера Datacol
Octoparse — это парсер для сайтов с визуальным интерфейсом, которая помогает собирать информацию с веб-сайтов без знания программирования. Она использует визуальный интерфейс и позволяет планировать работу парсеров. Octoparse предлагает библиотеку шаблонов, визуальную панель управления, экспорт данных в разные форматы, блокировку рекламы и настройку прокси-серверов. Эта программа полезна для аналитиков, директоров, трейдеров, маркетологов и других специалистов, работающих в сфере электронной коммерции.
Облачные парсеры
Облачные парсеры не требуют установки на компьютер. Доступ к результатам парсинга — через веб-интерфейс или по API.
Import.io — онлайн-инструмент для извлечения данных с веб-сайтов, их обработки и интеграции в базы данных. Сервис имеет функции самообучения, автоматического обновления и создания API. Он подходит для разных целей, например, мониторинга цен, анализа рынка и машинного обучения
Mozenda — это программа для корпоративного использования. Она работает на базе Windows и использует облачные технологии. С ее помощью можно извлекать данные из разных источников, загружать изображения, отслеживать историю изменений, планировать задачи, публиковать данные и многое другое.
Начало работы с программой Mozenda
CatalogLoader — программа для работы с товарами интернет-магазинов. Она автоматизирует основные процессы, такие как добавление товаров и их перенос на другие платформы. Возможности программы включают скачивание информации о товарах, изменение цен, создание иконок и импорт в разные CMS. Также она может сканировать товары с больших сайтов и мониторить цены конкурентов.
Diggernaut — это облачный сервис для парсинга сайтов и сбора данных. Он помогает анализировать информацию, загружать ее в облако и хранить там. Сервис умеет собирать разные типы данных: о продуктах, событиях, новостях, статистику и прочее.
У Diggernaut удобный интерфейс с инструментом Visual Extractor для настройки задач. Пользователи могут создавать роботов для очистки веб-страниц и сохранения данных. Diggernaut также поддерживает разные форматы вывода данных и интегрируется с другими платформами.
Главная облачного сервиса Diggernaut
Xmldatafeed — это сервис для парсинга цен на товары на онлайн-площадках и
мониторинга ассортимента. Он позволяет ежедневно анализировать цены и ассортимент на 500+ сайтах, отслеживать изменения и предоставлять данные клиентам.
Сервис автоматически собирает открытые данные с сайтов и предлагает готовые базы данных с информацией о товарах в форматах XML и CSV. Парсинг с Xmldatafeed полностью легален и соответствует законодательству РФ.
Парсеры в зависимости от технологий, которые они используют
В зависимости от используемых технологий, парсеры тоже можно разделить на несколько категорий.
Парсинг на основе Excel
Парсинг на основе Excel подойдет тем, кому нужен простой парсер товаров и контактов без программирования.
Такие программы используют макросы для автоматизации действий в Microsoft Excel, чтобы извлекать и выгружать данные в форматах XLS и CSV.
Один из примеров такой программы — ParserOK.
Начало работы с программой ParserOK
Парсинг с помощью Google Таблиц
Парсинг с помощью Google Таблиц — самый доступный способ веб‑скрапинга для маркетологов и SEO.
В Google Таблицы можно извлекать данные сайтов с помощью функций importHTML и importXML.
Функция importHTML позволяет импортировать данные из таблицы или списка на веб-странице.
Синтаксис функции следующий:
=IMPORTHTML(ссылка; запрос; индекс).
- Ссылка — это адрес веб-страницы с протоколом (http:// или https://).
- Запрос определяет, что нужно парсить: table (таблица) или list (список).
- Индекс — это порядковый номер таблицы или списка (начинается с 1).
Пример использования функции:
=IMPORTHTML(“https://orchidspa.ru/ceny-spa-salona/”; “table”; 1).
Переменные можно разместить в ячейках, и формула изменится следующим образом:
=IMPORTHTML(A1;B1;C1).
Так спарсили данные таблицы с сайта спа-салона:
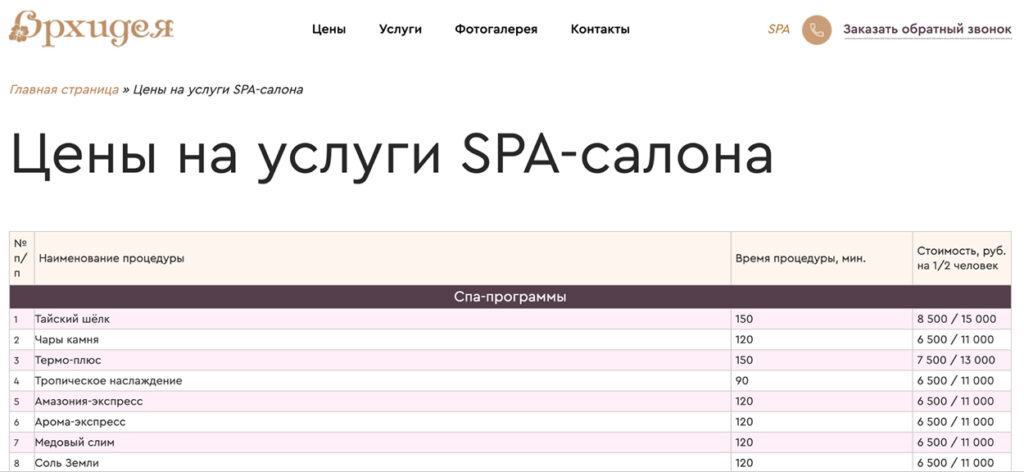
Таблицы с услугами и ценами на сайте
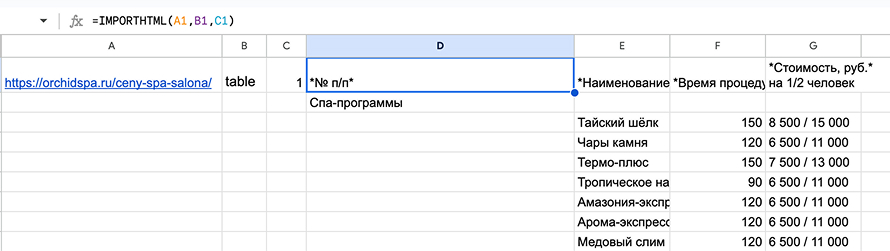
Данные из таблицы на сайте перенесены в Google-таблицу с помощью =IMPORTHTML
Функция importXML позволяет импортировать данные из источников в форматах XML, HTML, CSV, TSV, RSS и ATOM XML. В отличие от importHTML, она имеет более широкий спектр применения и позволяет извлекать информацию из различных частей страницы или документа.
Синтаксис функции importXML:
IMPORTXML(ссылка; “//XPath запрос”)
- Ссылка — это адрес веб-страницы с указанием протокола (http:// или https://). Значение этого параметра должно быть заключено в кавычки или представлять собой ссылку на ячейку, содержащую URL страницы.
- “//XPath запрос” — это то, что вы хотите импортировать.
Пример:
=IMPORTXML(“https://orchidspa.ru/ceny-spa-salona/”; “//a/@href”)
Значения переменных можно хранить в ячейках, тогда формула будет такой:
IMPORTXML(A1;B1)
Использование функций для парсинга просто освоить и для пользователя они совершенно бесплатные.
Парсеры-расширения браузера
Еще для сбора данных с сайтов можно использовать бесплатные расширения для браузеров. Они извлекают информацию из HTML-кода страниц с помощью специального языка запросов Xpath и сохраняют ее в удобных форматах для дальнейшего использования, например, в XLSX, CSV, XML, JSON, Google Таблицах и других.
Парсеры‑расширения браузера подойдут тем, кому нужно быстро забирать данные прямо во время работы в браузере: маркетологам, SEO‑специалистам, аналитикам и арбитражникам для разовых или небольших выгрузок без сложной настройки.
Вот несколько бесплатных расширений браузера Chrome, которые можно использовать для парсинга данных:
Web Scraper — инструмент для сбора информации с веб-сайтов. С его помощью можно создать схемы навигации по сайту и определить, какие данные нужно извлечь. Затем можно запустить парсер прямо в браузере и загрузить данные в формате CSV.
Web Scraper может извлекать данные с нескольких страниц, включая текст, изображения и URL-адреса. Расширение также работает с динамическими страницами, созданными с использованием JavaScript и AJAX, а также с бесконечной прокруткой. Вы можете просматривать собранные данные и экспортировать их в Excel.
Для использования этого расширения достаточно установить его в ваш браузер.
Старт работы с Web Scraper
Parsers — расширение для анализа данных с веб-сайтов. Оно помогает анализировать предложения конкурентов, отслеживать изменения цен и другое.
Алгоритм работы Parsers: пользователь выбирает нужные элементы на сайте и с помощью XPath отправляет адрес значения на сервер. Затем специальная программа анализирует сайт и находит страницы с таким же содержимым.
Программа извлекает информацию, которую указал пользователь, и сохраняет ее в файл. После обработки нужного количества страниц пользователь получает данные в отдельном файле, который можно скачать.
Parsers поддерживает форматы — XLS, XLSX, CSV, JSON, XML и передача через API
Data Scraper — инструмент для извлечения данных с веб-страниц в формате HTML и импорта их в Excel. Он полезен для тех, кому нужно загружать информацию в Excel для отчетов и исследований.
С помощью Data Scraper можно получать данные с разных сайтов, конвертировать их в форматы CSV, XLS, XLSX, TSV.
Начало работы с инструментом Data Scraper
Парсеры на основе Python и PHP
Парсеры на основе Python и PHP подойдут тем, кому нужны гибкие, масштабируемые и часто нестандартные решения: разработчикам, технарям в арбитраже и крупных проектах, где важен контроль логики парсинга, работа с большими объемами данных и глубокой автоматизацией.
Такие парсеры создаются программистами, здесь не справиться без специальных знаний. Помните, что создание парсера с нуля стоит заказывать только для нестандартных задач— для большинства целей есть хорошие готовые решения.
Самый популярный язык для создания парсеров — Python. Разработчики, владеющие этим языком, могут использовать библиотеки и фреймворки с открытым исходным кодом.
Самописные парсеры на Python и PHP
Scrapy (Python) — инструмент для веб-скрапинга (web scraping), разработанный на языке Python. Он предназначен для сбора данных с веб-страниц, представленных в формате HTML или XML, и предоставляет возможности для экспорта собранных данных в различные форматы, такие как JSON, CSV и XML.
Этот инструмент широко применяется в различных областях, включая интеллектуальный анализ данных, обработку информации и историческое архивирование.

Стартовая страница Scrapy (Python)
Selenium (Python) — инструмент для автоматизации работы с браузерами с помощью программного кода. Он часто используется для проверки веб-приложений и выполнения разных задач, связанных со сбором данных и веб-скрапингом.
Главная задача Selenium — автоматизировать действия пользователя в браузере, такие как перемещение по страницам, ввод текста, нажатие кнопок и многое другое. Это помогает разработчикам и тестерам создавать тесты, имитирующие поведение реальных пользователей, чтобы проверить работоспособность веб-приложения.
С помощью Selenium можно автоматизировать рутинные задачи, например, заполнять формы, регистрироваться на сайтах и собирать информацию. Также этот инструмент подходит для тестирования веб-приложений на разных устройствах и браузерах, а еще для создания скриптов для мониторинга сайтов и сбора данных
BeautifulSoup (Python) — это библиотека для парсинга HTML и XML документов в Python. Она предоставляет простой и удобный способ извлекать данные из веб-страниц, а также облегчает работу с этими данными.
Библиотека BeautifulSoup имеет удобный интерфейс для взаимодействия с HTML-кодом, что позволяет легко находить нужные элементы и извлекать из них информацию. Это делает ее популярной среди разработчиков, работающих с веб-скрапингом и анализом данных.
BeautifulSoup можно использовать для решения различных задач, связанных с извлечением данных, фильтрацией и манипуляцией информацией. Например, с ее помощью можно извлекать тексты, атрибуты, ссылки и другие данные из HTML/XML документов.
Главная страница библиотеки BeautifulSoup
Библиотека lxml (Python) — это инструмент для работы с HTML и XML. Она обладает простым интерфейсом, высокой производительностью и всеми основными функциями работы с этими форматами данных. Позволяет обрабатывать большие объемы XML и использовать инструменты XPath, XSLT и схемы для парсинга и анализа веб-страниц.
lxml обеспечивает быстрый и эффективный анализ данных, идеален для проектов с большим количеством информации. Поддерживает разные версии XML и HTML, а также работает с XSLT и XPath, позволяя разработчикам легко преобразовывать и фильтровать данные.
Преимущество lxml — простота использования, так как он написан на Python. Библиотека поддерживает Unicode, обеспечивая корректное отображение символов в разных языках и культурах.
Requests (Python) — это библиотека для упрощения работы с HTTP-запросами в языке Python. Она облегчает выполнение таких действий, которые в стандартной библиотеке требуют самостоятельной настройки. Библиотека Requests использует протокол передачи информации HTTP и текстовый протокол для автоматизации многих процессов
PHP Simple HTML DOM Parser — это программа для работы с HTML-документами на языке PHP. Она помогает искать, менять и брать информацию с веб-страниц.
Возможности программы:
- загрузка HTML-кода (из строки или файла);
- извлечение данных из элементов HTML;
- изменение содержимого HTML-страницы;
- поиск элементов с использованием CSS-селекторов;
- преобразование DOM обратно в HTML.
Simple HTML DOM Parser подходит для сбора данных, автоматизации задач и работы с веб-страницами.
Начало работы с Simple HTML DOM Parser
Виды парсеров по задачам и специализации
Выбор программного обеспечения или облачного сервиса для парсинга зависит от конкретных задач, которые нужно решить.
Если мы делим по задачам, то есть четыре основных типа парсеров:
- универсальные,
- для оптимизации SEO,
- для мониторинга конкурентов,
- для сбора информации и автоматического заполнения контента.
Универсальные парсеры
Многофункциональные парсеры способны собирать данные для различных задач, таких как заполнение интернет-магазинов, мониторинг цен конкурентов, анализ данных и многое другое. К ним также относятся браузерные расширения с функцией парсинга.
Когда выбирать такой тип парсера: когда нужно собирать разные типы данных (товары, цены, контакты, контент) из множества источников и решать сразу несколько задач без узкой специализации.
К универсальным парсерам можно отнести:
ParseHub — это онлайн-парсер в облаке, который работает как универсальный парсер для сайтов с визуальной настройкой сбора данных. Он собирает любые данные и не требует особых навыков. Пользователи могут легко настраивать процесс парсинга с помощью функции drag-and-drop.
Это инструмент для сбора информации, который позволяет загружать полученные данные в разных форматах для дальнейшего анализа.

Стартовая страница онлайн-парсера ParseHub
К рангу многофункциональных парсеров можно причислить и Import.io, ParserOK, Mozenda, OctoParse и DataCol. О них немного подробнее уже упоминалось в этой статье.
SEO-парсеры
Парсеры используются для всестороннего анализа веб-сайтов — внутренней, технической и внешней оптимизации. Некоторые парсеры имеют скромный набор функций, а другие представляют собой мощные инструменты для SEO.
Когда выбирать такой тип парсера: когда важен детальный технический и контентный аудит сайта — метатеги, заголовки, коды ответов, индексация, внутренняя перелинковка и другие SEO‑показатели.
Задачи SEO-парсеров:
- проверка корректности настройки основного зеркала;
- анализ содержания robots.txt и sitemap.xml;
- определение наличия, длины и содержания метатегов title и description, количества и содержания заголовков h1–h6;
- определение кодов ответов страниц;
- создание XML-карт сайта;
- определение уровня вложенности страниц и визуализация структуры сайта;
- проверка наличия или отсутствия атрибутов alt у изображений;
- поиск битых ссылок;
- проверка наличия атрибута rel=“canonical”;
- предоставление информации о внутренней перелинковке и внешней ссылочной массе;
- отображение данных о технической оптимизации (скорость загрузки, валидность кода, оптимизация для мобильных устройств) и другое.
Примеры нескольких SEO-парсеров:
MegaIndex — сервис для анализа и продвижения сайтов, который можно использовать как SEO‑парсер для оценки ссылочного профиля и видимости в поиске Google и Яндекс. Он собирает информацию о сайте из интернета и хранит ее в своей базе данных, делает сравнение видимости с конкурентами, подбирает и кластеризирует ключевые слова.
Главная страница сервиса MegaIndex
Screaming Frog SEO Spider — программа для технического аудита сайтов, которая работает как парсер для технического анализа структуры, метатегов и ссылок. Ее нужно скачать на компьютер с операционными системами Windows, macOS или Linux. В программе 29 инструментов, которые помогают искать ошибки в URL, метатегах и ссылках, а также анализировать страницы и проверять канонические ссылки.
Ahrefs — это веб-инструмент для анализа сайтов, изучения социальных сетей, обратных ссылок, ключевых слов и упоминаний бренда, который отлично подходит как SEO‑парсер для исследования ссылочного профиля и поискового трафика. Он помогает анализировать работу конкурентов, объединяя маркетинговые и SEO-инструменты.
Возможности Ahrefs включают:
- сбор и анализ входящих ссылок,
- определение числа ссылающихся доменов и страниц, графики по динамике ссылок и доменов,
- поиск битых бэклинков,
- фиксацию типов бэклинков,
- показ динамики трафика и ключевых слов,
- поиск наиболее цитируемых страниц,
- показ анкор-фраз и анкор-терминов,
- аудит сайтов.

Стартовая Ahrefs
Netpeak Checker — многофункциональный инструмент для массового анализа URL, который используется как SEO‑парсер для быстрой проверки большого количества страниц по ключевым метрикам. Он позволяет парсить выдачу поисковых систем, настраивать язык, страну и другие параметры, а также ограничивать вид сниппетов.
Эта программа проверяет индексацию страниц в Bing, Yahoo и Google и поддерживает использование прокси и сервисов для решения капч. Можно сортировать, группировать и фильтровать данные, а затем экспортировать отчеты для дальнейшей работы с ними
A-Parser — мощный инструмент для работы с поисковыми системами и данными, который можно применять как SEO‑парсер для сбора выдачи, ключевых слов и метрик сайтов. Работает также с сервисами оценки сайтов, контентом (текстом, ссылками, данными) и другими сервисами (YouTube, картинками, переводчиками).
A-Parser поддерживает платформы Windows и Linux, имеет веб-интерфейс с возможностью удаленного доступа, позволяет создавать собственные парсеры без написания кода и сложные парсеры на языках JavaScript и TypeScript с поддержкой модулей NodeJS. В парсере есть более 90 встроенных инструментов.
Интерфейс A-Parser
Semrush — платформа для анализа конкурентов и поиска ключевых слов, которая работает как комплексный SEO‑парсер для отслеживания позици и трафика, анализа обратных ссылок.
Возможности Semrush включают комплексный анализ конкурентов, исследование ключевиков, отслеживание позиций и анализ обратных ссылок.
Serpstat — сервис для оптимизации SEO‑стратегии, который выступает как SEO‑парсер для анализа запросов, конкурентов и видимости сайта.
Основные преимущества Serpstat:
— анализ ключевых слов,
— анализ конкурентов,
— аудит сайта,
— мониторинг позиций сайта по заданным ключевым словам,
— анализ обратных ссылок,
— кластеризация запросов.
Стартовая страница сервиса Serpstat
Netpeak Spider программа для аудита сайтов, которая используется как парсер для технического аудита и поиска проблем внутренней оптимизации. Она может собирать информацию по списку адресов или в рамках одного сайта, поддерживает четыре вида поиска (по содержимому, CSS, регулярным выражениям и языку запросов XPath) и позволяет задать до ста поисковых условий.
Также программа извлекает контакты, проверяет микроразметку, анализирует атрибуты HTML-тегов и выгружает полученные данные в файлы для дальнейшей работы с ними в Excel.
SiteAnalyzer от Majento — бесплатная программа для анализа сайта, которая работает как парсер для технического SEO‑аудита и поиска ошибок на страницах. Она сканирует страницы, изображения, скрипты и документы, определяет коды ответов сервера, Title, Description, H1–H6, canonical, robots.txt, robots и другие параметры.
Программа также проверяет уникальность контента, скорость загрузки страниц, ссылочный анализ и генерацию карты сайта.
Начало работы с программой SiteAnalyzer от Majento
Semonitor — набор инструментов для продвижения сайтов, который можно использовать как SEO‑парсер для анализа структуры, ссылок и позиций в поиске.
Semonitor включает такие функции:
— анализ сайта (определение битых ссылок, структуры сайта, уровня PR);
— анализ логов (выявление посещаемости, запросов пользователей, региональной принадлежности);
— анализ PageRank (определение PR, тИЦ, присутствия в каталогах, числа внешних ссылок);
— анализ HTML (вычисление плотности и веса ключевых слов, анализ содержания страниц, конкурентов);
— подбор ключевых фраз (оценка конкуренции, ранжирование по соответствию запросам);
— определение позиций (показ позиций в поисковых системах);
— анализ внешних ссылок (составление списка, анализ динамики, анализ конкурентов);
— обмен ссылками (поиск подходящих площадок для обмена);
— индексация сайта (показ количества проиндексированных страниц).
SE Ranking — сервис для управления SEO‑процессами, который выступает как SEO‑парсер для мониторинга позиций, аудита и анализа конкурентов.
Вот некоторые из функций, доступных в сервисе:
— подбор ключевых слов (частотность определяется с помощью сервисов Google Keyword Planner и Яндекс Wordstat);
— кластеризация ключевых слов;
— технический аудит;
— мониторинг позиций (отслеживает позиции сайта в результатах поиска);
— анализ конкурентов.
Главная сервиса SE Ranking
ComparseR — специализированное ПО для анализа индексации, которое работает как SEO‑парсер для сравнения сайта с поисковым индексом Яндекса и Google.
ComparseR имитирует поведение поискового робота: сканирует все доступные для индексации страницы, собирает их основные параметры и сохраняет их в таблице.
Кроме того, программа анализирует поисковый индекс сайта. В результате пользователи могут видеть, как сайт индексируется, все ли его страницы участвуют в поиске.
Парсеры для мониторинга конкурентов
Эти парсеры помогают поддерживать конкурентоспособные цены в интернет-магазине. Они отслеживают цены на заданных ресурсах, сравнивают товары и их стоимость с вашим каталогом и позволяют корректировать цены для привлечения покупателей. Парсеры мониторят сайты конкурентов, обновляемые прайсы в форматах XLS, CSV и других, а также маркетплейсы, такие как Яндекс Маркет, Wildberries, e-katalog и другие прайс-агрегаторы.
Когда выбирать такой тип парсера: когда нужно регулярно отслеживать цены, ассортимент, акции и изменения на сайтах конкурентов или маркетплейсах, чтобы вовремя корректировать собственные предложения
В качестве примеров подобных парсеров можно перечислить эти:
Priceva — сервис для анализа цен и акций конкурентов, а также автоматической переоценки товаров.
Возможности сервиса включают:
— анализ цен, наличия, скидок и акций;
— автоматическая переоценка по заданным формулам;
— гибкая настройка расписания проверок;
— рассылка об изменениях цен и акциях;
— автоматическое сопоставление ассортимента;
— мониторинг цен с учетом размеров, цветов и технических особенностей товаров;
— импорт и экспорт данных;
— сквозной анализ товарной номенклатуры;
— уведомления о демпинге;
— мониторинг в разных валютах;
— API-интеграция.

Главня сервиса Priceva
Сервис работает по подписке, есть бесплатная демо-версия с ограниченным набором функций.
uXprice — это сервис для мониторинга и анализа цен конкурентов в интернете. Он обеспечивает 100 % точность информации, быстро подключается и отслеживает до 100 конкурентов на один товар. Сервис анализирует цены качественно и предоставляет много показателей.
Чтобы начать использовать uXprice, нужно зарегистрироваться и добавить товары на платформу. Сервис может мониторить цены ежедневно или по заданному графику
ALL RIVAL — это парсер сайтов и инструмент для мониторинга цен конкурентов. Он предназначен для аналитиков, маркетологов и контент-менеджеров интернет-магазинов.
Основные функции парсера:
— анализ стоимости товаров,
— формирование рекомендованных цен,
— скачивание каталогов товаров,
— сбор новостей и отзывов,
— анализ профилей пользователей в социальных сетях.
Сервис работает автоматически и предоставляет отчеты в формате XLS.
Главная страница парсера ALL RIVAL
Marketparser — это программа для отслеживания цен на разных торговых площадках и в интернет-магазинах, независимо от их местоположения. Она позволяет автоматически собирать информацию о ценах, анализировать продукты конкурентов, выбирать частоту мониторинга, извлекать данные и создавать прайс-листы.
Также сервис уведомляет об изменениях и предоставляет возможность экспорта данных. Он будет полезен владельцам интернет-магазинов и тем, кто продает товары на маркетплейсах.
Парсеры для сбора данных и автонаполнение контентом
Такие парсеры упрощают работу контент-менеджеров интернет-магазинов, автоматически собирают данные с сайтов-доноров (товары, цены, изображения и прочее) и загружают их на сайт или в файл.
В настройках можно установить наценки, объединить данные с нескольких источников и настроить автоматический сбор данных по расписанию или вручную.
Когда выбирать такой тип парсера: когда важно автоматически тянуть товары, описания, изображения и характеристики с сайтов‑доноров и загружать их в каталог или базу без ручного копирования.
Для подобных манипуляций подойдут парсеры Catalogloader, Диггернаут и Xmldatafeed.
Как выбрать парсер под свои задачи: чек-лист критериев
Коротко — какие есть варианты:
- определиться с бюджетом: подходят платные парсеры или только бесплатные решения;
- установить подходящую программу для парсинга;
- поручить программисту, если такой человек есть в штате, разработать парсер с учетом конкретных потребностей;
- обратиться в компанию, которая создаст парсер специально для вас (это будет стоить дороже).
С двумя последними вариантами все понятно: платишь — получаешь готовый продукт. С первыми двумя немного сложнее: нужно поискать подходящие под конкретные задачи инструмент и выбрать из нескольких вариантов.
Чтобы определиться, какой парсер выбрать, пройдите по чек-листу:
| Критерий | На что смотреть | Что это дает |
| Цель парсинга | Что именно нужно собирать: цены (нужен парсер для мониторинга цен), карточки товаров, парсер для SEO(метатеги, позиции), контент, данные конкурентов. | Помогает сразу отсечь лишние инструменты и не переплачивать за функции, которые не нужны. |
| Объем и регулярность | Разовая выгрузка или постоянный мониторинг (ежедневно, почасово, по триггерам). | Понимаетe, нужен ли простой разовый парсер или полноценный сервис с расписанием и логированием. |
| Формат данных на выходе | Какие форматы критичны: CSV, Excel, Google Таблицы, API-интеграция. | Обеспечивает удобную загрузку данных в отчеты, CRM, BI, рекламные кабинеты и другие системы. |
| Автоматизация и расписание | Есть ли задачи, которые должны запускаться сами: по расписанию, по событию, без ручного клика. | Позволяет настроить полностью автоматический сбор данных без ежедневной рутины. |
| Прокси и антикапча | Нужны ли прокси, антикапча, ротация IP, обход блокировок и лимитов запросов. | Дает стабильный сбор данных даже с «чувствительных» сайтов, которые режут частые или массовые заходы. |
| Уровень подготовки | Если вы новичок — проще начать с облачных сервисов и браузерных расширений; для сложных, кастомных задач подойдет Python‑/парсер для мониторинга цен/ или самописный /парсер для SEO/. | Помогает соотнести сложность инструмента с вашими навыками, чтобы не «утонуть» в настройках. |
Почему важно знать, что такое парсер
Парсеры — это полезные инструменты для автоматизации процессов и облегчения работы специалистов разных областей.
Эта подборка парсеров могет пригодиться арбитражникам, маркетологам, SEO-специалистам и другим. Использование парсеров позволяет сэкономить время и усилия, повышая при этом качество работы и эффективность выполнения задач.
Тем не менее, помните про парсер, что это — важная часть сетапа арбитражника, и к его выбору следует отнестись ответственно. Прежде всего, определите, какие именно функции вам необходимы, и решите, готовы ли вы потратить часть средств на разработку собственного парсера или предпочитаете бесплатные парсеры.
FAQ
Что такое парсер простыми словами?
Легально ли использовать парсеры и веб‑скрапинг?
Какой парсер выбрать новичку?
Какие есть бесплатные парсеры для сайтов?
Чем отличается парсер от сканера сайта?
Что выбрать: парсер или готовый сервис мониторинга цен и конкурентов?
Чем полезен парсинг для арбитража трафика и маркетинга?
Нужен ли отдельный парсер для SEO и техаудита?
Материалы по теме















Вставить свои 5 копеек: