


Еще интересные детали про новые модели от DeepSeek
Еще интересные детали про новые модели от DeepSeek
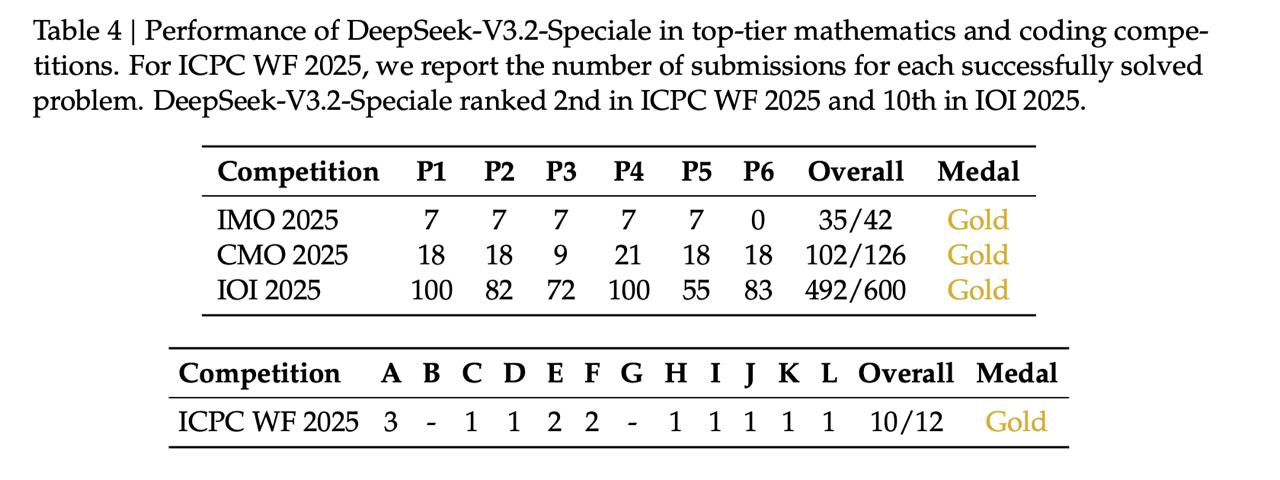
➖ DeepSeek-V3.2-Speciale – это первая опенсорсная модель, которая выбивает золото в топ-олимпиадах. Обратите внимание на рисунок 1: золото на IMO 2025, CMO 2025, IOI 2025 и ICPC WF 2025. Но test-time compute при этом огромен: Speciale совсем не экономит токены, так что инференс достаточно дорогой.
➖ Еще раз про метрики (прикрепляем расширенные таблички): Speciale бьет Gemini 3.0 Pro на математике, а «менее умная» DeepSeek-V3.2 опережает Claude-4.5 Sonnet в кодинге (примерно уровень GPT-5 Pro). В случае с Speciale снова обратите внимание на количество используемых токенов, оно указано в таблице 3 в скобочках. Выглядит совсем не эффективно, и авторы сами говорят, что «оставили оптимизацию на будущие исследования».
➖ Основные технические причины успеха моделей: DeepSeek Sparse Attention, масштабный стабильный RL-тренинг и большой пайплайн для Agentic Tasks. Обо всем по отдельности – ниже.
1️⃣ DeepSeek Sparse Attention. Новая архитектура внимания и, по сути, ключевое изменение архитектуры по сравнению с предыдущим поколением. Состоит из двух частей: Lightning Indexer и Top-k sparse selection.
Lightning Indexer решает, какие прошлые токены важны для текущего. Работает довольно дешево и просто выдает индекс важности каждому query для всех предыдущих токенов. Top-k sparse selection выбирает top-k самых важных. Во время претрейна сначала обучается только индексер, потом основная модель размораживается и обучается уже полностью.
В итоге сложность вычислений падает с O(L²) до O(L·k). Помимо ускорения работы DSA дает еще резкое улучшение способностей на длинном контексте.
2️⃣ Посттренинг. Во-первых, очень масштабный этап RL-дообучения. В RL вложили примерно десятую часть того, что было потрачено на pretraining. Это беспрецедентно много, обычно это 1% или меньше. Обучали все также с GRPO, но в модифицированном виде. Там несколько архитектурных подвижек, о них читайте в статье. В двух словах: стало гораздо стабильнее и теперь метод хорошо масштабируется.
Во-вторых, использовали Specialist Distillation. Сама моделька MoE, но фишка в том, что каждый эксперт (в широком понимании слова) обучается как бы отдельно. То есть на основе базовой DeepSeek-V3.2 обучают набор узких моделей (типа specialist-math, specialist-coding и тд), а затем их знания дистиллируют в основную модель. Накладываем на это вышеупомянутый RL – и вот вам вау-качество в нескольких доменах.
3️⃣ Ну и Agent Training. Модельки чрезвычайно хороши во всяких агентских задачах, и особенно в browsing/search. У DeepSeek был очень сильный agent-пайплайн. Модель долго учили сохранять ризонинг при использовании инструментов, потом делали Cold-Start Training на tool call, а затем вообще генерировали 1800+ cинтетических сред, в которых агенты обучались выполнять совершенно разные задачи c помощью RL. В общем, у них там получилась целая фабрика задач.
Релиз – огонь. Поздравляем DeepSeek с возвращением! 🐋
Техрепорт полностью читаем здесь











Вставить свои 5 копеек: