


Если хочешь получать лучшие результаты от LLM без оплаты за длинные аутпуты…
Если хочешь получать лучшие результаты от LLM без оплаты за длинные аутпуты или файн-тюнинг, вот конкретный, элементарный финт:
Дублируй свой промпт!
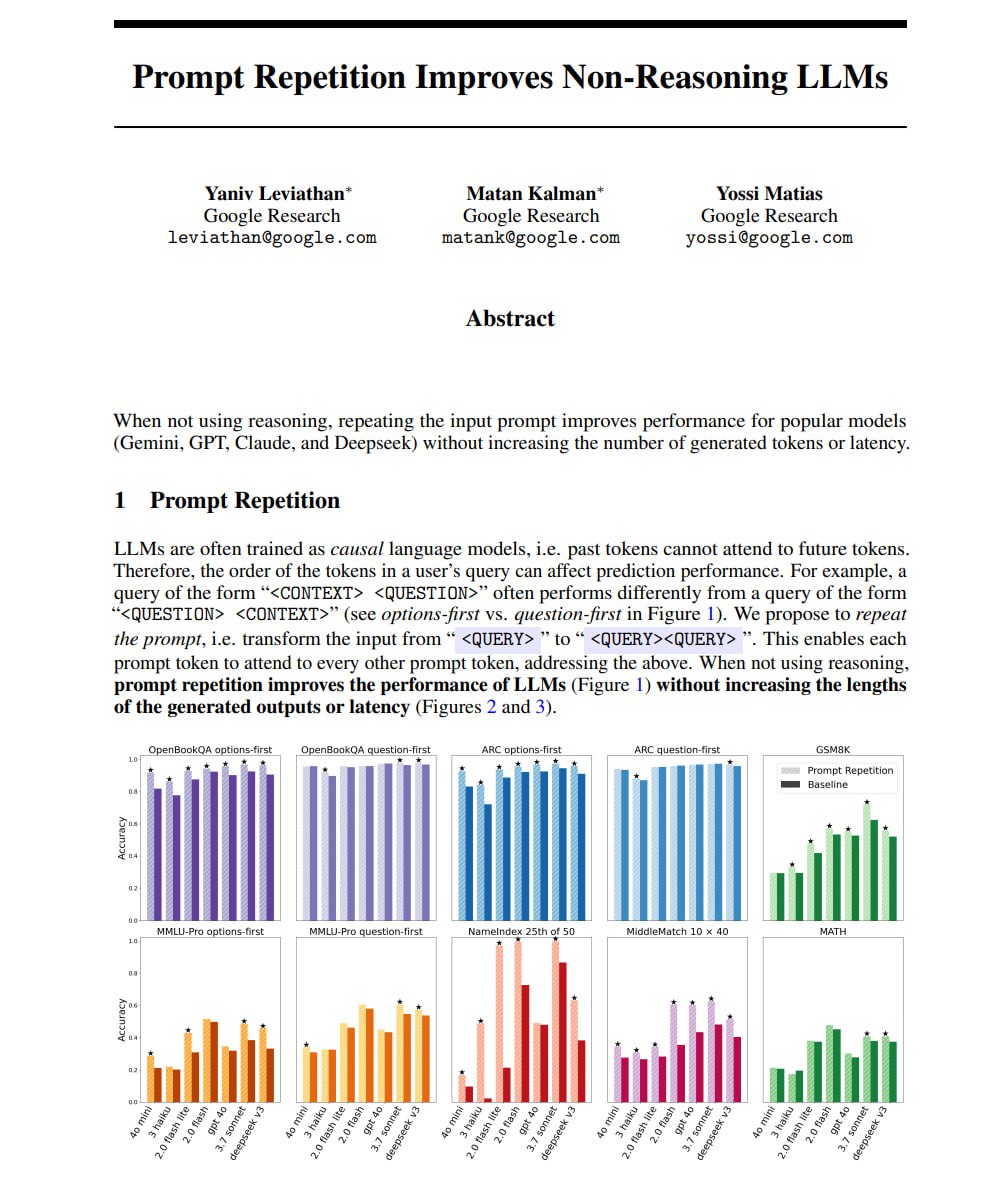
Исследователи обнаружили, что повторение абсолютно того же самого инпута может драматически улучшить перформанс (буст до 76% на конкретных задачах).
LLM процессит текст слева направо, каждый токен может смотреть только на предыдущий контекст, никогда — вперед.
Поэтому, когда ты пишешь длинный промпт с контекстом в начале и вопросом в конце, модель может опираться на этот контекст для ответа, но контекст был обработан до того, как модель вообще узнала вопрос.
Эта асимметрия — базовое структурное свойство того, как работают LLM.
Повторение промпта помогает обойти это ограничение, давая модели второй проход по полному контексту.
Здесь нет вычисления новых потерь и никакого замудренного промпт-инжиниринга.
Это просто структурный хак, который работает почти на каждой крупной модели, которую они тестировали.
Вот пейпер: https://arxiv.org/pdf/2512.14982
#LLM #AI #Automation
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
Материалы по теме












{kind=link}
Вставить свои 5 копеек: