


Google выпустили SOTA модель для генерации речи
Google выпустили SOTA модель для генерации речи
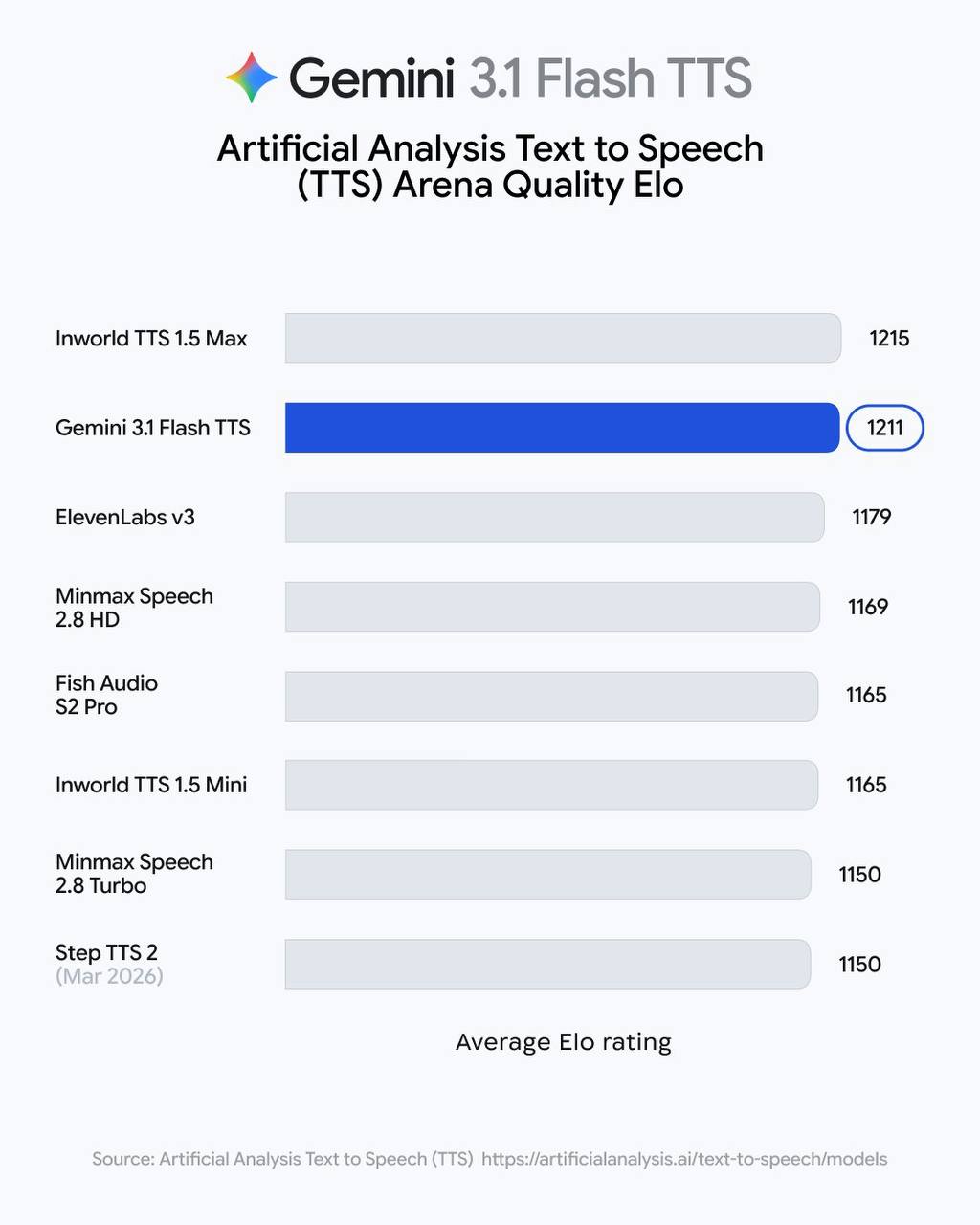
Вышла Gemini 3.1 Flash TTS – новое поколение голосового движка в экосистеме Gemini.
Киллер-фича: суперточный контроль интонации. Возможно задавать стиль, темп, ударения и «атмосферу» речи через теги в тексте, почти как в режиссерских заметках для голоса.
Плюс модель может работать с многоголосием с сохранением стиля голоса каждого персонажа, так что ее можно использовать для озвучки целых фильмов.
Плюс скорость. По сравнению с более ранними TTS ускорение первого токена и общей задержки произошло на десятки процентов. Это уже близко к полноценным онлайн прод-сценариям.
Озвучка, переводы, ИИ-подкасты и голосовые агенты скоро выйдут на совсем новый уровень
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-tts/
Материалы по теме











Вставить свои 5 копеек: