


Как работает Google Search: Поясняем за Retrieval и Ranking
Как работает Google Search: Поясняем за Retrieval и Ranking
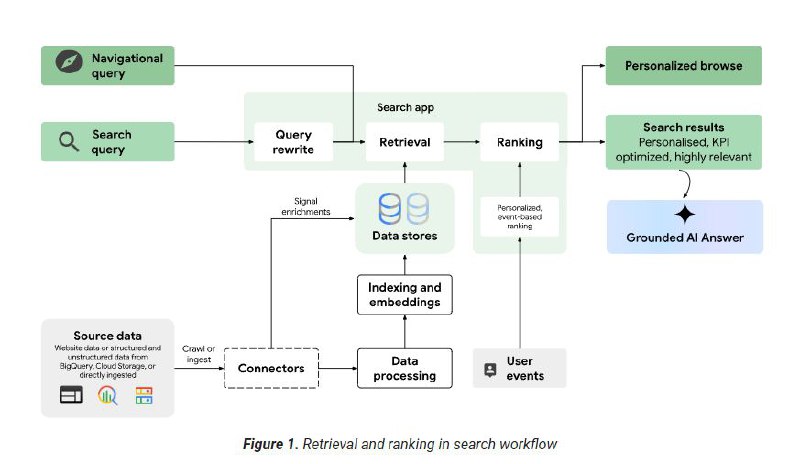
Согласно официальной доке Vertex & Cloud, подход Гугла к выдаче результатов — это двухфазный процесс: сначала Retrieval (сбор широкого пула потенциально релевантных документов), а затем Ranking (ранжирование этого сабсета для финальной презентации).
Ранжировать вообще все доступные доки было бы слишком затратно по ресурсам, отсюда и последовательность.
1. Retrieval: Поиск кандидатов
Начальный этап: поисковая модель понимает запрос юзера и переписывает его, затем определяет большой сабсет доков (потенциально тысячи) из своих огромных хранилищ, которые релевантны.
Этот процесс опирается на различные сигналы для присвоения начального скора релевантности:
📍Topicality (Топикальность): Сюда входит традиционное совпадение по ключам, инсайты из графов знаний и более широкие веб-сигналы.
📍Embeddings (Эмбеддинги): Продвинутые модели юзают эмбеддинги, чтобы находить концептуально похожий контент, выходя за рамки точного вхождения ключей.
📍Cross-attention: Позволяет модели анализировать сложные связи между запросом и документом для присвоения скора релевантности, захватывая глубокие контекстуальные связи.
📍Freshness (Свежесть): Возраст документов — важный фактор, гарантирующий приоритет актуальной инфы, когда это уместно.
📍User Events (События юзеров): Сигналы конверсии, показывающие, как юзеры взаимодействуют с контентом, внедряются для персонализации.
2. Ranking: Упорядочивание по релевантности
Как только доки собраны (retrieved), модель ранжирования берет этот сабсет и пересортировывает его, присваивая новый скор релевантности на основе нескольких условий.
Из тысяч изначально найденных модель обычно отдает топ-400 ранжированных результатов.
Ключевые методы ранжирования:
📍Boost (Буст): Механизм позволяет поднимать или опускать определенные результаты на основе кастомных атрибутов (например, звездный рейтинг, популярность) или свежести.
📍Search Tuning (Тюнинг поиска): Этот процесс конкретно влияет на то, как модель воспринимает семантическую релевантность документов, и корректирует скоры релевантности эмбеддингов.
Особенно полезно для уточнения поиска под специфические индустриальные или брендовые запросы.
📍Event-based Reranking (Переранжирование на основе событий): Персонализированные результаты доставляются путем обновления ранжирования прямо в момент выдачи, используя модели персонализации на основе user-events.
#Rankings #Embeddings #SemanticSEO
@MikeBlazerX
Но самое «мясо» — в @MikeBlazerPRO
Материалы по теме












{kind=link}
Вставить свои 5 копеек: